3 advanced JavaScript concepts you should master next

In this article, I’d like to cover three advanced JavaScript concepts that I found very interesting and challenging.
Applying these concepts will take you on a journey to explore the deeper JavaScript topics and quirks. Some of the building blocks required for the implementations include asynchronous programming, currying, higher-order functions, closures, scope, and classes. I’ll put links to learning resources at the end of the article.
We are covering concepts like function call rate limiting, asynchronous flow control, and memoization, which among others, are commonly used on the web, and chances are, you’ve seen some of them in action while reaching this article.
Function call rate limiting is a common pattern used on search bars or scroll behaviors. Applying it significantly decreases the number of requests made to the server or the calls to a function that executes a costly operation. While the function call rate limiting optimizes the number of executions of a function, caching and memoization optimize costly operations that are known to produce the same result for the same input. Of course, caching is a huge and complicated topic, and in this article, we will explore only small and fairly simple implementations. Asynchronous JavaScript is a core building block of the language, considering its single-threaded nature. It’s used for handling potential blocking operations on the thread, like fetching resources from the server. Mastering the flow of operations can take you to the next level as a developer, and might open the door for creative solutions to problems.
Let’s start with…
Function call rate limiting
Throttling and debouncing are techniques that every JavaScript developer should know. They are used to limit the execution of a function that’s called frequently and repeatedly, as performance optimizations on the web, especially on the user events that can be triggered consecutively. For example, API calls on user input or costly JavaScript calculations on scroll.
Both techniques offer similar benefits but are quite different in their implementation and usage.
Throttling is a technique where we apply a rate limit to the executing function so it’s not executed again unless N amount of time has passed. This does not prevent the function from being called, it just adds a rate limit to the number of calls that can occur over a period of time, for example, one call per second. If you have a function that tracks mouse movements and executes code each time the mouse moves, you may want to throttle the inputs so that the JavaScript only fires a limited number of times over a set period. Doing so minimizes the impact on the user’s device.
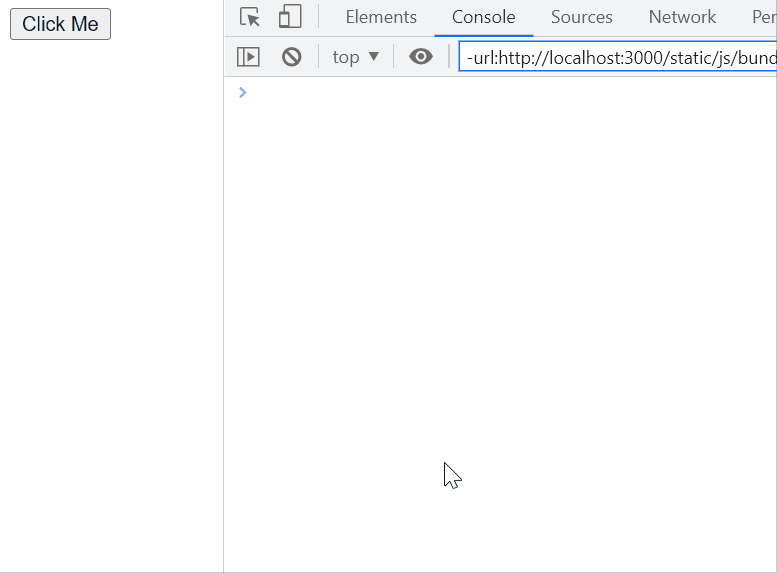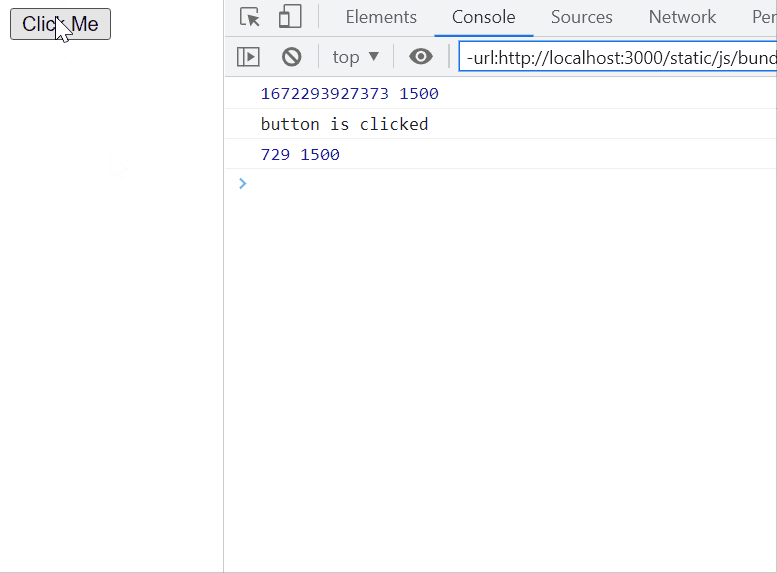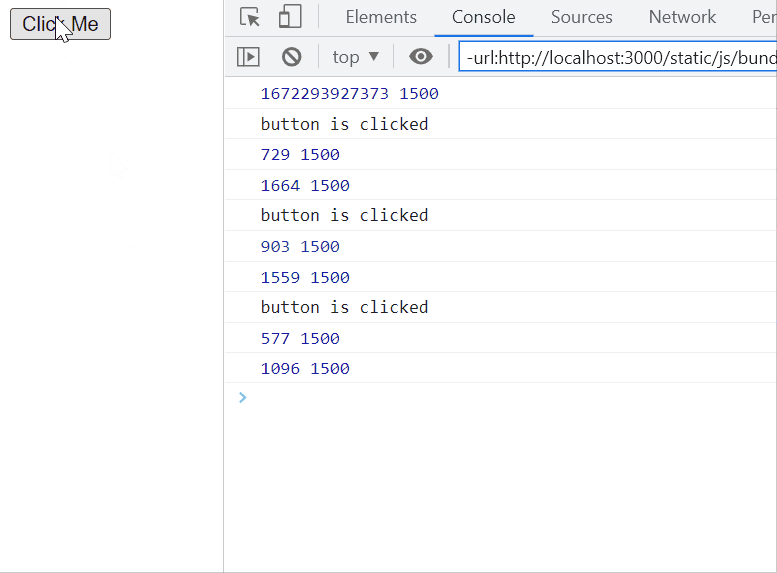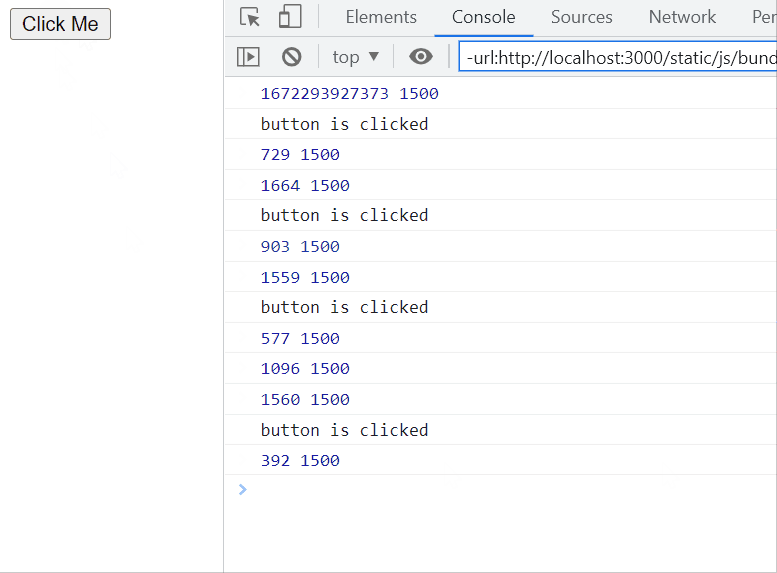
Debounce, on the other hand, is used to block the first and all the succeeding calls within a specified amount of time of each call, until the specified amount of time has passed from the last call. Then, the last call is executed. Confusing? Easier to explain with an example.
This technique is good for API calls, especially on API calls triggered from user input, like a search bar that searches as the user is typing. By debouncing a search bar, when the user quickly types ‘cat’, instead of making 3 calls on the search endpoint, for ‘c’, ‘ca’, and ‘cat’, our function calls the API only when the user stops typing and executing the search only for ‘cat’.

There are robust implementations of these functions, like debounce and throttle from lodash that are ready to be used out of the box. We will implement a simplified version of them.
Problem statement: Rate limit - Once [Basic]
Design a function once(fn) that adds a limit to the execution of the function fn so it can be executed only once.
Explanation
The once function is defined to accept a function fn as its parameter. By returning another function, this classifies as a higher-order function. once encloses the returned function with a scope that includes a variable called that keeps track of whether the function has been executed once or not, and the original function passed as an argument.
Executing the returned function for the first time called is false, and the original function will be executed. Additionally, called becomes true. For every subsequent call of the returned function, called is going to be true, and the original function will never be called.
This pattern is useful for scenarios where you need to limit the execution of certain code to a single instance, such as initialization logic or event listeners. By using this approach, you can prevent redundant operations and avoid potential issues related to multiple executions of a function that should only run once.
Problem statement: Rate limit - Throttle [Medium]
Design a function throttle(fn, interval) that adds a rate limit to the number of calls that can occur on the function fn over a period of time interval.
Bonus points for preserving the last throttled call and executing it with the correct rate.
Explanation
Similarly, the throttle function is defined to accept a function fn and a time interval interval, making it a higher-order function. Inside throttle, a variable named timer is declared and initialized to null. This variable will act as a timer to manage the rate limiting.
When executed, the returned function first checks if timer is null. If it is, it means that the original function is ready to be executed with the provided arguments. When it is executed, we set timer using setTimeout. This timeout will be the mechanism that ensures the original function is not executed again before the specified interval passes. If the function is called again before the timeout ends, the original function won’t execute. When the timeout ends, then the timeout is cleared and the timer variable is set back to null, allowing the next call to execute the original function.
For the testing part, due to the throttling mechanism, fn (in this case, console.log) is only executed once per second, regardless of the more frequent attempts.
Preserving the last throttle
Adding the preservation of the last function call and executing it once the timer ends is now easy. We can do that by introducing another variable lastFn that will store the last function call. And we store it only when the interval has not passed. Otherwise, when the timer ends, we execute the stored function call.
This implementation will help us to implement a more complicated problem later.
Problem statement: Rate limit - Debounce [Medium]
Design a function debounce(fn, interval) that adds a rate limit to the function fn so it can execute only after interval milliseconds have passed since the last call to the debounced function fn.
Explanation
The debounce function has the same basis and it works very similarly. The difference is with what we do with the timeout. The debounce function returns a new function that first checks if timer is already set. If it is, clearTimeout is called to reset the timer. Then, setTimeout is used to set a new timer that will call fn with the provided arguments after the specified interval has passed. This ensures that fn is only executed if there are no new calls to the debounced function within the interval period.
Let’s take the ‘cat’ example from before. Assuming fn is a function that makes the API calls for searching with the typed characters in an input field and interval is 300ms. The user types ‘c’ and the denounced function is called. This sets the timeout to 300ms and plans to execute the API call when it ends. But because our user types fast, they enter ‘a’ in 150ms, which resets the timer to 300ms again and postpones the API call. Same thing with ‘t’, but after entering the last letter, they stop typing. The 300ms timeout ends, and then the API call is executed, having the whole word ‘cat‘ available for searching. Implementing debounce, we saved two redundant and costly operations on the server.
Problem statement: Rate limit - Throttle with limit and queue [Advanced]
Design a function rateLimit(fn, limit, interval) that limits calls to fn such that it can only be called limit times per interval milliseconds. If the function is called more often, the additional calls should be queued and executed at the correct rate.
Explanation
We will design the rateLimit function to accept three arguments. The function fn we want to limit, the limit for the number of allowed calls, and an interval in milliseconds used for throttling. This is where the implementation of the throttle function with preserving the last function call comes in handy. Here, instead of storing the last function call, we will store them all in a queue , and instead of trying to execute fn immediately, we go through the following process:
Add the function to the queue and call
execute.Inside
executeIf thequeueis empty, it clears the timer and returns. Nothing to execute.Else, if
callsis less than thelimit, it sets a timer if one is not already running. The timer is set for the specifiedinterval, and when it fires, it resetscallsto 0, clears the timer, and attempts to execute up to the limit of queued calls again.If the call limit has not been reached, it shifts the next set of arguments from the
queue, incrementscalls, and invokesfnwith those arguments.
The execute function is a recursive function that calls itself in interval ticks. This works well in this situation because this higher-order function supports synchronous functions. In the next section, we will explore a way to limit asynchronous functions too.
Asynchronous flow control
The other day I was creating an interesting tool at work aimed to help with automating the cookie governance of the company as part of the general GDPR compliance. Not to go too deep into details, but one of the main challenges was building a Node.js script that should run some memory-intensive, asynchronous operations. This is a long-running process, that can be parallelized to the extent of how much the current device that runs it allows. The challenge was apparent, build a robust asynchronous runner that can effectively always run up to N operations in parallel.
Implementing async control algorithms requires a deep and clear understanding of JavaScript’s asynchronous nature. As we know already, JavaScript is a single-threaded language. This means that some expensive computations, like loading scripts or making API calls can block the thread and make the whole application unusable until they finish. For this reason, JavaScript and its runtimes, whether in a browser or server-side with Node.js, work together to make the magic happen. It’s called an event loop.
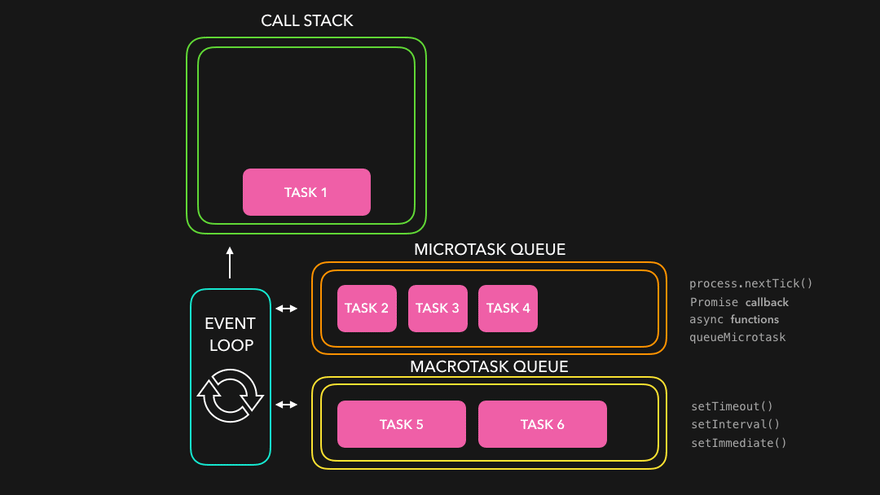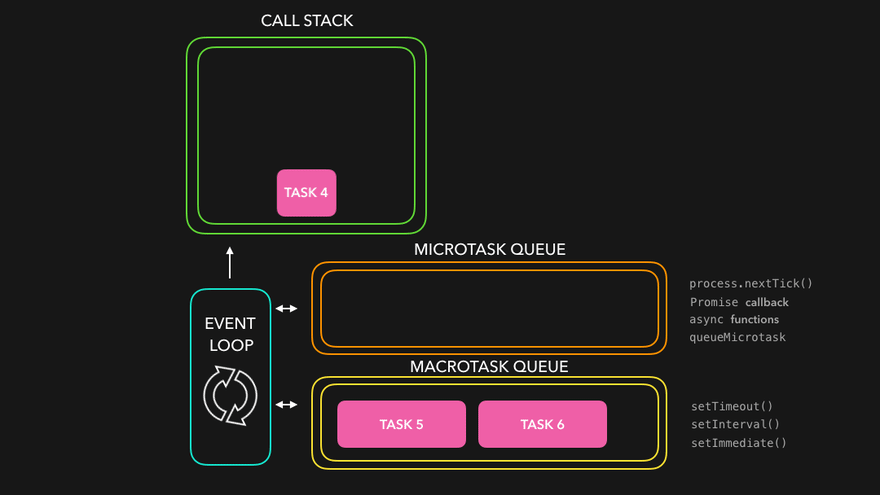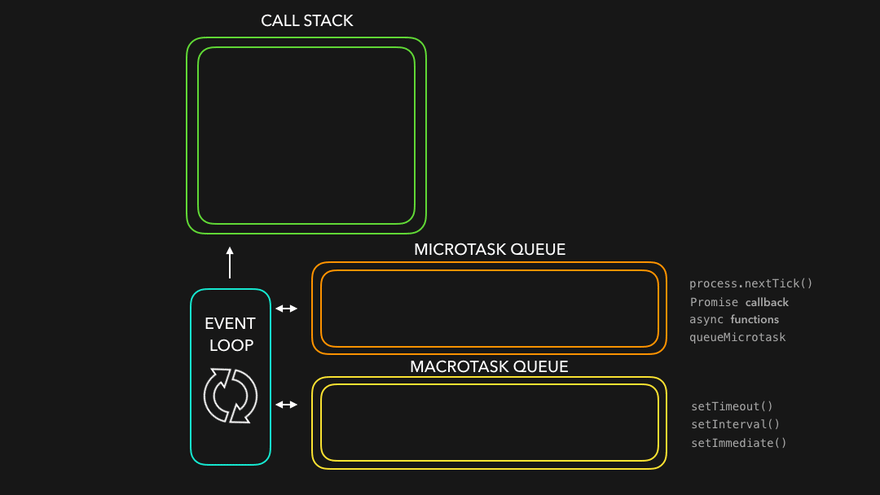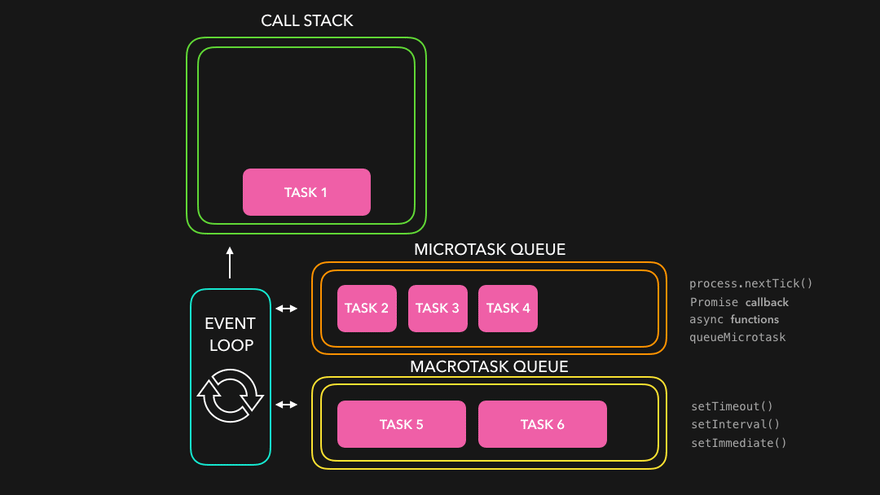
Credits to Lydia for the awesome visualizations. Make sure to check out her 7-part series “JavaScript Visualized”
I’m not going to explain the workings of the event loop and how async JavaScript works in this article. You can read more about it in the article I linked above, or below in the “Read more” section. However, mastery over it is required to solve the following problem statements.
Let’s warm up with…
Problem statement: Promise.all() with timeout [Medium]
Design a function promiseAll(tasks) that behaves like Promise.all(), but adds additional features such as timeout for each promise. The function should return a promise that resolves when all the tasks are completed or rejects if any of the tasks fail. If a task doesn't resolve within the specified timeout, it should be rejected.
Explanation
This problem has a perfect use case for Promise.race(). The trick is to let two asynchronous events compete which one resolves first. One is the original asynchronous task, the other is a timeout that expires in timeout milliseconds. If the first resolves before the second, then the original asynchronous function is resolved successfully. However, if the second one wins, it means the original promise timed out. This is the moment of time when we need to timeout the whole operation. Each task in the array is effectively replaced by this race condition, ensuring that the task completes within the given time frame or fails if it exceeds the timeout.
The function accepts two parameters: tasks, an array of functions that return promises, and timeout, the duration in milliseconds for each promise. To achieve this, promiseAll returns a Promise that resolves if each tasks races resolve or any to reject.
Each task in the tasks array is transformed to include a timeout mechanism. For each task, a timeout promise is created using setTimeout. If the timeout is reached, the promise is rejected with a "Task timed out" error. Simultaneously, each task is wrapped in a Promise.resolve().then() to ensure it returns a promise.
Would you be able to modify this function to mimic Promise.allSettled(), but with timeout?
Problem statement: Async Task Runner with concurrent limit [Advanced]
Implement a Runner class, which manages task execution with a specified concurrent limit. This limit determines how many tasks can run simultaneously. If the limit is reached, any additional tasks should be queued and executed only after some of the currently running tasks have been resolved. This ensures efficient task management by maintaining a balance between concurrent execution and queuing so that the Runner class can process tasks in an orderly and controlled manner. Bonus points: The class should support adding priority tasks.
Explanation
In the constructor, the Runner class initializes the concurrent limit, the count of currently running tasks, a queue for regular tasks, and a separate priority queue. The add method is used to add new tasks to the runner. It accepts a task and an optional priority flag. If the priority flag is true, the task is added to the priority queue; otherwise, it is added to the regular queue. After adding the task, the execute method is called to start processing tasks.
The execute method is responsible for managing the execution of tasks. It checks if the number of running tasks is less than the concurrent limit. If so, it retrieves a task from the priority queue if available; otherwise, it retrieves a task from the regular queue. If there are no tasks to execute, the method returns. If a task is found, it increments the running task count, executes the task, and decrements the running task count once the task is completed. The execute method is then called recursively to continue processing any remaining tasks.
To demonstrate the functionality of the Runner class, a sample task function is defined. This function takes a parameter and returns another function that returns a promise. The promise simulates a task by using setTimeout to wait for 2 seconds before logging a completion message and resolving.
An instance of the Runner class is created with a concurrent limit of 3. Several tasks are added to the runner, some with priority and some without. The tasks are processed according to the concurrent limit, with priority tasks being executed before regular tasks. This demonstrates how the Runner class effectively manages concurrent task execution and queuing.
This pattern is handy in scenarios where you need to control the number of concurrently running tasks, such as managing API requests, handling file uploads, or processing jobs in a background worker.
Caching and memoization
Caching is a concept that by definition, means making resources available for quicker access. It’s a concept in computer science that is widely applied in every component. From caching on the hardware level to caching on the system level to caching on the application level like e.g in the browser for resources loaded from a server.
Memoization is a caching technique widely used in the web development world. It helps save resources by allowing a function to serve stored results from previous computations instead of doing the same computation again for the same input. One of the most famous explicit memoization functions is React.useMemo() hook. useMemo works in a way that allows the function passed as an argument to be memoized and to return the same result without re-calculating for every re-render unless any of the members of the dependency array changes. Vue’s computed() works similarly but with the dependency array defined implicitly.
Problem statement: Memoized function [Medium]
Create a function named memoize(fn) that accepts a function as its argument. The purpose of the memoize function is to cache the results of the provided function fn. When the memoized function is called with the same arguments in the future, it should return the cached result instead of recalculating it. This will optimize performance by avoiding redundant calculations.
Explanation
The memoize function accepts a single argument, fn, which is the function to be memoized. Inside memoize, a cache is created using a Map to store the results of previous function calls. The function returns a new function that takes any number of arguments using the spread operator.
When the returned function is called, it converts the arguments into a string argsKey to use as a key for the cache. It then checks if the cache already contains a result for these arguments. If a cached value exists, it is returned immediately, bypassing the function call.
If there is no cached value, the function fn is called with the provided arguments, and its result is stored in the cache with argsKey as the key. The result is then returned. This ensures that the next time the function is called with the same arguments, the cached result is used instead of recalculating it.
To demonstrate the memoize function, consider a function times2 that takes a number and returns its double. The times2 function includes a console log to indicate when it is called. This helps to see when the function is actually executed versus when a cached result is used.
The memoize function that I implemented has one flaw. Usually, the cache functions have limited size because it’s important for the cache to stay in a manageable size, so it can return stored results efficiently. Would you be able to change the function to support a cache size limit too?
In addition to the cache size limitations, the caching structures usually implement cache replacement policies. These policies are used to determine which entries to be replaced when the cache reaches its limit. One such policy is the Least Recently Used policy, or LRU.
Problem statement: Least Recently Used (LRU) Cache [Medium]
Implement an LRUCache class with get and put methods. The cache should have a capacity and should invalidate the least recently used item before inserting a new item when the capacity is reached.
The constructor initializes the cache with a specified capacity and uses a Map to store the cache items. The Map is chosen because it maintains the insertion order and provides O(1) time complexity for access operations. This makes it well-suited for the requirements of an LRU cache.
The put method is responsible for inserting key-value pairs into the cache. If the cache size exceeds the capacity, the least recently used item (the first item in the Map) is removed. This ensures the cache does not grow beyond its limit. If the key already exists in the cache, it is removed first to update its position to the most recently used, before re-adding the key-value pair to the cache.
The get method retrieves the value associated with a given key. If the key exists in the cache, the method deletes the key and re-inserts it to update its position to the most recently used, ensuring the accessed item is marked as recently used. If the key does not exist, the method returns undefined.
To demonstrate the LRUCache class, consider an instance created with a capacity of 3. Initially, items 'a', 'b', and 'c' are inserted into the cache. When the item with key 'a' is accessed using the get method, it is moved to the most recently used position. Next, item 'd' is inserted. Since the cache is at capacity, the least recently used item, 'b', is removed to make space for 'd'. The item with key 'c' is then updated with a new value, '5', moving it to the most recently used position. Finally, when item 'e' is inserted, the least recently used item, 'a', is removed to accommodate the new item.
Conclusion
The three topics that we covered are concepts that are very relevant in modern web development. Even though there are ready-to-use functions that you should use because of their robustness, a deep understanding of those concepts can prove useful in recognizing the opportunity where you can improve the performance of your applications, saving some resources along the way.
Additionally, these concepts, among others, are commonly asked in front-end or full-stack developer technical interviews. The implementation of these concepts requires a deep understanding of JavaScript and its building blocks and mechanisms, like the single-threaded nature of the language for example, which requires being extra careful in handling asynchronous behavior, because otherwise, it can greatly affect the customer satisfaction from the speed of our application, or worse, the correctness of the result.
That’s why it’s important to explore and play around with related, but different implementations beyond the ones in this article.
You can find all the implementations on my GitHub page or Codepen.
Read more:
Debounce vs Throttle: Definitive Visual Guide - kettanaito.com
Asynchronous JavaScript - Learn web development | MDN (mozilla.org)
Illustrations borrowed from https://www.geeksforgeeks.org/
If you enjoyed this article, share it on your favorite social network. It means a lot to me!
Published on 29.05.2024
Edited on 21.11.2024 - Replaced the event loop animation.